Inbound Pipeline: Difference between revisions
(No difference)
| |
Latest revision as of 10:27, 24 June 2021
This article describes the DDS inbound pipeline that takes raw data from publishers and transforms them to a standard format.
Technical overview

Multiple applications make up the inbound pipeline:
- White boxes represent DDS applications.
- Arrows show the communication method between components.
- Not all databases are shown.
- Interaction with databases have been simplified.
Input: CSV, TSV, fixed-width, HL7v2 data from multiple publishers.
Output: FHIR resources, stored as JSON in EHR databases, for the Outbound Pipeline to use.
Databases
- Multiple databases are used in the inbound pipeline
- Architecture is designed to avoid cross-database joins, so databases do not need to be co-located on the same instance
- In production DDS instance, there are approx. 10 database instances
- All database access layer code in EdsCore repository (except for SFTP Reader and HL7 Receiver applications)
| Database Name | Platform | Description |
|---|---|---|
| Admin | MySQL | Stores details on services publishing to and subscribing from the DDS |
| Audit | MySQL | Stores audit of published data and transformations to it |
| Config | MySQL | Stores most configuration including database connection strings, logging, RabbitMQ routing |
| Eds | MySQL | Stores patient demographics (duplicated from the FHIR in the ehr database) and details of patient-person matching |
| Ehr | MySQL | Stores all patient and reference data in FHIR JSON. There is support for multiple ehr databases, with each publishing service configured to write to a specific ehr (many to one) |
| Fhir_audit | MySQL | Stores record-level audit of mapping from published data to FHIR |
| Hl7_receiver | PostgreSQL | Stores all state and configuration for HL7 Receiver application. This application is PostgreSQL-only. |
| Publisher_common | MySQL | Stores resources for transforms that are not publisher specific. For example, stores Emis code reference data, which is common to all Emis publishers. |
| Publisher_transform | MySQL | Stores persistent mappings from published data IDs to DDS UUIDs, at the service level. Each ehr database has a corresponding publisher_transform database. |
| Reference | MySQL | Provides standard reference data from TRUD and ONS e.g. SnomedCT, Read2, OPCS-4, ICD-10, postcodes |
| Sftp_reader | PostgreSQL & MySQL | Stores all state and configuration for SFTP Reader application. Note that this application can run on PostgreSQL (in DDS live) and MySQL (everywhere else) |
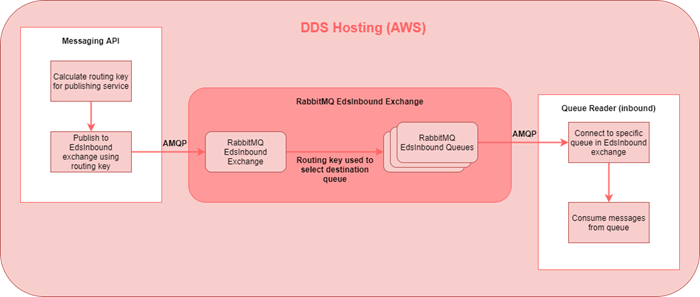
RabbitMQ
- RabbitMQ has two concepts exchanges and queues
- Each queue is bound to an exchange
- Each exchange may have multiple queues bound to it
- Publishing to RabbitMQ is done to an exchange, with a routing key
- The exchange uses the routing key to select the destination queue, this is configured as part of the binding between exchange and queues
- Consuming from RabbitMQ is done from a queue and simply returns queued messages in order

Applications
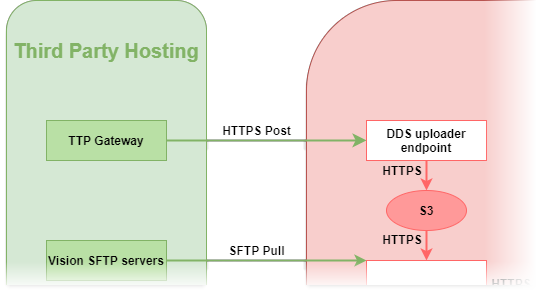
DDS Uploader Endpoint
- Special API endpoint for uploading TPP data to DDS for TPP-specific way of extracting data
- Not used for anything else
- Purpose solely to receive TPP data from SystmOne Gateway and store in S3
- Endpoint technically part of Messaging API (in same War file) but no overlap with other Messaging API functionality

| Property | Value |
|---|---|
| Component type: | Tomcat servlet (part of Messaging API) |
| Code location: | eds-messaging-api module in eds repository |
| Arguments: | n/a |
Processing steps:
- TPP Gateway zips TPP extract data (CSV files) into 10MB multi-part zips
- TPP Gateway sends zip fragments to Endpoint using HTTPS over HSCN
- Endpoint combines zip fragments
- Endpoint validates data is for an expected publisher
- Endpoint writes combined zip to pre-defined S3 path

SFTP Reader
- Entry point for flat-file data formats (e.g. CSV, TSV) into transformation pipeline
- Detects and downloads new data on remote third party SFTP servers (e.g. Emis, Vision)
- Detects new data in S3 pushed to DDS by third parties (e.g. TPP, Barts)
- Prepares file for transformation but does not processing of the data content itself
- Notifies Messaging API of newly received data
- Maintains state in its own database (sftp_reader)

| Property | Value |
|---|---|
| Component type: | Java application |
| Code location: | SFTPReader repository |
| Arguments: | Instance name – tells it what publishers to check for data, relates to “instance” table in DB. Note other arguments are supported for specific one-off tasks, but aren’t used for normal operation. |
For each configured data source (TPP, EMIS, Vision etc.):
- Checks remote SFTP server / checks local S3 for new files
- Downloads new files
- Decrypts and decompresses*
- Validates files*
- Splits files into per-organisation sets**
- Writes output files to S3
- Store details on new files in database
- Notifies Messaging API of new data via HTTPS post containing list of file paths
*These steps vary depending on the format of the published data
**Some extracts contain data for multiple organisations within each file, so each file is split into separate ones containing just one organisation each

HL7 Receiver
- Entry point for ADT data into transformation pipeline
- Receives real-time ADT messages in HL7v2 format using MLLP protocol directly from publishing hospital TIEs (Trust Integration Engine)
- Transforms HL7v2 messages to FHIR resources before sending to Messaging API using HTTP POST
- Maintains transform mappings and state in its own database (hl7receiver)
- Database is PostgreSQL (not migrated to MySQL yet)

| Property | Value |
|---|---|
| Component type: | Java application |
| Code location: | HL7Receiver repository |
| Arguments: | n/a |
For each publishing trust:
Receiver Thread
- Establish MLLP connection
- Receive incoming HL7v2 message
- Write to hl7receiver database message table
Processing Thread
- Read unprocessed messages from database
- Transform HL7v2 to FHIR
- Notify Messaging API via HTTPS Post containing transformed FHIR

Messaging API
- Common gateway for all new data published into DDS
- SFTP Reader and HL7 Receiver POST to Messaging API
- Validates POST message contents
- Writes received messages to audit database
- Publishes received messages to RabbitMQ to be picked up by Inbound Queue Readers
- Frailty API and DDS Uploader Endpoint are also part of the Messaging API war file but not functionally related

| Property | Value |
|---|---|
| Component type: | Tomcat servlet |
| Code location: | eds-messaging-api module in eds repository |
| Arguments: | none |
For each HTTPS Post:
- Extract organisation and data format identifiers from HTTP header
- Validate organisation is known
- Validate organisation has a Data Processing Agreement (i.e. that DDS is allowed to process the data)
- Validate data format is expected from publishers
- Create “Exchange” from HTTP body and headers *
- Store Exchange in audit database
- Publish Exchange to EdsInbound RabbitMQ exchange **
* Not to be confused with RabbitMQ exchange concept
** RabbitMQ routing key is typically calculated from publisher ODS code

Inbound Queue Reader
Queue Reader is a multi-purpose app for consuming messages from RabbitMQ. Depending on configuration, runs in one of four modes:
- Inbound – transforms published data in various formats into standardized FHIR
- Protocol – calculates subscribers for new published data *
- Transform – performs outbound transforms from standard FHIR format *
- Subscriber – sends outbound transform results to a specific subscriber *
* Part of outbound transformation pipeline and not covered in this document

| Property | Value |
|---|---|
| Component type: | Java application |
| Code location: | eds-queuereader module in eds repository, but all transform logic in transforms repository |
| Arguments: | Config ID – tells it what config record to use which determines which queue is consumed from and what type of Queue Reader it is. Note other arguments are supported for specific one-off tasks, but aren’t used for normal operation. |
Each Inbound Queue Reader instance connects to a single RabbitMQ queue in the EdsInbound exchange:
- Consume message from RabbitMQ
- Verify message should be transformed - if previous for same publisher went into error, new messages will automatically do the same *
- Select relevant inbound transform based on data format
- Transform published data to FHIR
- Save FHIR to EHR DB, save mappings to publisher_transform DB, save demographics to eds DB
- Post to RabbitMQ EdsProtocol exchange to invoke outbound transformation pipeline – one message is published per patient affected by the transform, containing the patient UUID
- ACK message in RabbitMQ queue (remove from queue)
* In production DDS, messages in error will be removed from the RabbitMQ queue and must be manually re-queued using DDS-UI when ready for processing – this prevents the message blocking the queue and stopping messages for other publishers being processed. In development environments, messages will generally be left on the top of the queue and the Queue Reader application will simply exit

DDS-UI
- Internal webapp for managing and monitoring the inbound pipeline
- Displays audit of data published for each service
- Displays current state of various components (SFTP Reader, HL7 Receiver, Queue Readers)
- Used to configure publishing services
- Used to configure RabbitMQ queues and routing of publisher services to queues
- Used to re-queue messages into RabbitMQ for re-processing (after a bug has been fixed) – publishes into EdsInbound exchange

| Property | Value |
|---|---|
| Component type: | Tomcat servlet and Angular2 frontend (no plans to migrate to Angular8 as it’s an internal tool) |
| Code location: | eds-ui module in eds repository |
| Arguments: | none |